Om mitt svar til "Hva blir utviklernes største utfordring i 2020? 😲"
Bakgrunn
Den 9. desember 2019 stilte kode24-redaksjonen følgende spørsmål på deres facebook-gruppe “kode24-klubben” (krever medlemskap):
Hva blir utviklernes største utfordring i 2020? 😲
- og svarene der ble da lest opp på deres podcast kode24-timen episode #10.
Jeg tok oppfordringen og startet på det som endte opp som en litt komprimert tirade, men det ble allikevel litt langt - og ikke nødvendigvis så podcast-vennligt - hvorpå på det ble sagt at dette kanskje kunne være bedre i bloggformat. Så, here goes!
Den opprinnelige kommentaren kan leses i sin helhet nederst.
TL;DR
Alt jeg kommer til å skrive nedover kommer til syvende å siste handle om at man må vurdere kost mot nytte, samt ta litt samfunnsansvar. Utfordringen er ofte at nytten eller verdien ved å anvende eller inkorporere et gitt språk, rammeverk, arkitektur/design-pattern, modul e.l. er åpenbar; De respektive løsningene har jo blitt tatt frem for å løse gitte problemer, mens kostnadene kan være mange og gjerne ikke gi seg til kjenne før langt senere.
Jeg mener dermed utviklernes største utfordring vil være å med høyere presisjon vurdere - og dermed bedre agere på - de reelle kostnadene ved sine valg, eventuelt sett fra den andre siden; bli nødt til å ta konsekvensene av tidligere slike valg.
Kommentaren, tema for tema
Jeg vil her gå igjennom de ulike aspektene jeg tok opp i kommentaren. Da jeg favner ganske bredt i alt jeg er innom så vil jeg riktignok heller ikke her gå så dypt som jeg kanskje kunne på noen av de. Hensikten til denne posten er primært å få det hele inn i en mer strukturert form, samt gi det litt mer fylde og med dette danne grunnlag for fremtidige innlegg hvor jeg der heller går mer i dybden på de individuelle aspektene.
- Obs: Jeg er ikke på noen måte den første til å observere eller mene noe som helst av det jeg skriver her. Ingen ære til meg her. Bakgrunnen for å iterere/repetere over dette er fordi jeg føler det fortsatt fokuseres for lite på mange av disse aspektene.
- Obs2: Full åpenhet: Mine egne løsninger svarer heller ikke ut alle mine bekymringer - men jeg tilstreber det alltid innenfor de rammene jeg har å jobbe med, forsøker alltid å selv bli bedre, og har ikke minst: alltid kost:nytte med i de store og små vurderingene man fortløpende gjør gjennom alle fasene av et utviklingsløp. Dette er ikke binært - eller? \*wink wink*
Om gjenbruk
Det har blitt gjentatt og gjenfortalt så mange ganger i så mange former at man ikke skal finne opp på nytt hva som allerede er funnet opp. Argumentet som blir gjort her er gjerne at det du selv improviserer sammen av en funksjon ikke er like godt kvalitetssikret som noe tredjepartskode, samt at det vil koste deg mere tid (og dermed, i mange tilfeller, penger) enn om du finner en eksisterende løsning og bruker denne.
Dette er ikke kategorisk feil, men etter min mening tas dette i mange tilfeller for langt og/eller gjøres uten tilstrekkelig vurdering av de reelle kostnadene dette har.
De mer eller mindre generelle ferdigløsningene der ute er lagd med forutinntatte antakelser om hvordan de skal brukes, som kanskje eller kanskje ikke stemmer med dine faktiske omgivelser (f.eks. arkitektur og generell kodestil i prosjektet du jobber i).
Tar vi i tillegg dette opp på et makroperspektiv og krisemaksimerer litt ekstra så risikerer vi kanskje også redusert innovasjon og i verste fall at verdifull kompetanse innen enkelte problemområder kan gå tapt og må gjenlæres. Samfunnsøkonomisk sett vil jeg slå et slag for at det er viktig og riktig å iblant revurdere gamle løsninger på gamle problemer i tillegg til å løse de så langt uløste problemene.
Ser man da på at mange slike løsninger også inneholder mer kode/funksjonalitet enn du trenger i ditt scenario legger kan man da ofte legge på en gjentakende kostnad for enten deg eller dine brukere, f.eks:
- Kompileres den så må det tolkes og prosesseres
- Sendes det til nettleser så er det ekstra data både å sende og å tolke
- Og selv om mye kan optimaliseres bort så gir du her ekstra arbeid til ett eller annet sted i bygge-pipelinen din og på det vis øker det fortsatt tiden du bruker for hver iterasjon
I tillegg har du de velkjente problemene rundt hvorvidt løsningen er vedlikeholdt, at du opererer innenfor lisensvilkårene, og avhengig av hvordan du spesifiserer dine avhengigheter så kan du være utsatt for senere introduksjon av feil i nye versjoner. Du er uansett ansvarlig for ditt sluttprodukt.
Jeg kunne også skrevet litt om misoppfatninger rundt "DRY" og "design patterns"-misbruk også - men det får bli for en annen gang.
Om abstraksjoner
En abstraksjon er i all sin enkelhet et forsøk på å trekke seg unna, skjule, eller på annet vis å beskrive noe annerledes enn slik det originalt ble gjort (wikipedia, webster). I programvareutvikling forsøker man ofte å abstrahere for å:
- gjemme detaljer man ikke ønsker å trenge forholde seg til til vanlig - f.eks. gjentakende kode eller kompliserte operasjoner som kanskje krever spesiell kunnskap for å mestre (f.eks. algoritmer)
- definere og skille moduler/komponenter/subsystemer man ønsker å frikoble seg fra for å enklere kunne teste, erstatte og/eller jobbe med uavhengig av hverandre
- kunne støtte multiple varianter/tilbydere av en funksjon/subsystem (f.eks: periferiutstyr, plugins)
Man kan selvsagt også argumentere for at enhver form for enkapsulering av noe (f.eks. en funksjon) er en form for abstraksjon, men jeg tenker her på de litt større, bevisste, arkitekturelle eller designmessige valgene man gjør.
I tillegg så ser man i lys av "dependency injection"-bølgen at enkelte prosjekter velger å beskrive formelle grensesnitt for enhver klasse, og (min favoritt</sarkasme>) registrerer alle disse i et container-system som automagisk slår opp og genererer de faktiske objektene eller hva det nå skulle være på bakgrunn av dette.
Felles for de alle er at noen da gjør en vurdering om hvilke muligheter og hva slags data som skal skjules og eksponeres, og definerer dermed et grensesnitt basert på dette.
Risikoen her kommer da til syne når man først har laget en abstraksjon, og denne har blitt tatt i bruk over både tid og rom, og det kommer et behov for å revidere denne på et vis som bryter bakoverkompatibilitet. Ligger denne abstraksjonen på et tilstrekkelig høyt nok nivå i arkitekturen så har man kanskje iverksatt et versjoneringsregime for å håndtere denne typen endringer, men uansett ligger det da en kost i å enten oppdatere alle konsumenter, eller å ivareta multiple løsninger i parallell. Men i tillegg til de eksplisitte avhengighetene så har vi de implisitte avhengighetene man hadde lurt seg til å tro man var trygg for takket være at man hadde lagd nettopp disse fine abstraksjonene.
For min del er utsagn som "Dette språket er SÅ høynivå at du ikke trenger å tenke på minnehåndtering|raceconditions|parallelitet" eller "Dette rammeverket abstraherer vekk alle dine \
Om kompleksitet, ytelse, maskinvare og utviklertid
Hvert nytt lag av noe som helst du legger på løsningen din øker kompleksiteten. Dette, ironisk nok, til tross for at lagene ofte introduseres for å skjule kompleksitet. Det er også uavhengig av om dette gjøres direkte i koden, i bygge-pipelinen, i deployment-regimet eller i infrastrukturen ellers. Dette er da hensyn som på ulike tidspunkt vil måtte være en del av utviklerens kognitive belastning når du enten vurderer konsekvensen av funksjonen du legger til, eller er på lusejakt.
Det er et knippe utsagn jeg gjør i kommentaren som går innom disse temaene:
Argumenter som at utviklertid er mer kostbar enn hardware møter seg selv når man
mansnubler over bugs og flaskehalser som kommer fra alt fra underliggende årsaker som man enten ikke forstår til utilstrekkelige og/eller dype abstraksjoner som det vil være fryktelig kostbare å endre [...]
Igjen: dette kommer tilbake til en kost:nytte-vurdering. Man kan alltids iterere, simplifisere og/eller optimalisere inn i evigheten - det er ikke det jeg mener man skal. Men gi det noen runder, og vær klar over implikasjonene det har å legge til nye dimensjoner til en løsning. Rich Hickey har noen gode poeng rundt enkelt vs simpelt - spesielt definisjonsmessig - som er bra å ta med seg. Han går riktignok der ikke inn på temaet kjøretidsytelse. Hovedpoenget han gjør er å presisere at det er forskjell på noe som er en lett tilgjengelig løsning for deg, nå, sammenliknet med hva som er en ukomplisert løsning som er lett å forstå og jobbe med også i ettertid.
[...] det er ikke akkurat som at OSene vi har i dag er veldig HW-effektive og robuste heller... Dette av historiske grunner, men dog.
Det jeg refererer til her er det at de fleste større allment brukte operativsystem bærer med seg en stor teknisk gjeld og et sett bakoverkompatibilitetsrelaterte problemer knyttet til blant annet behov for å støtte en stor mengde ulike perifere enheter og systemarkitekturer. Og i noen av disse tilfellene legger da operativsystemet seg på et "minste fellesnevner"-nivå mtp anvendelse av hardwarekapabilitetene, og realiserer ting som nå i mange tilfeller er løst i hardwaren/firmwaren til periferienheten i software i stedet (Se f.eks. denne om potensiell ytelsesgevinst ved å retenke hva ansvaret til et operativsystem kan være). Dette byr på flere linjer kode som i ulik grad tar med seg en eller flere av utfordringene jeg nevner i denne posten, i tillegg til at det hører til sjeldenhetene at kode eksekvert på en CPU for generelle formål (CISC/RISC) utklasserer spesialisert firmware kjørende på/for dedikert maskinvare. Casey Muratori gjorde noen interessante betraktninger noen år tilbake rundt det med at vi nå ikke lenger eksperimenterer like mye rundt arkitekturer og typer perifere enheter og sånn sett kunne hatt mye å hente på å flytte litt mer ansvar til hardware, revidere systembusgrensesnittet og på det viset redusere mye av hva et operativsystem ville trengt å være. Jeg er ikke selv nødvendigvis 100% enig i alt det han konkret legger frem, men finner det vanskelig å være uenig i det store bildet.
[...] det ikke er uvanlig å høre argumenter som at "ubrukt RAM er sløst RAM" [...]
Obs: Dette er min subjektive tolkning av et knippe ulike utsagn hørt igjennom tidene, samt hva som oppleves som å være praksis med tanke på den mengde ressurser generelt, og RAM spesielt, som brukes normalt i dag.
Beslektede argumenter her er at RAM er så billig eller at målgruppen din kanskje uansett har så-og-så mye RAM allikevel.
Dette er kanskje et av de mest problematiske problemstillingene jeg kommer borti når jeg som en utvikler av ganske så beskjedne systemer må ha 16GB+ med RAM bare for at jeg ikke skal havne i minneswaporamaland. For meg vitner dette om manglende respekt for sluttbrukerens tid og ressurser.
Sånn jeg ser det er denne type utsagn kun gyldig i noen tilfeller der du vet uten tvil at ditt system er det aller viktigste (les: typisk eneste) som kjører på den gitte maskinvaren/ressursbassenget i perioden det måtte gjelde - eller om du gir brukeren mulighet til å kontrollere dette. Det hjelper ikke at operativsystemet forsøker å være intelligent når applikasjonen enten ikke er ærlig om sine reelle behov, eller bare helt enkelt er overkonsumerende.
Vi nyttiggjør oss ofte heller ikke veldig mye av den veldig avanserte maskinvaren vi nå etterhvert har fått, med effektive løsninger rundt pipelining, cachehåndtering, branch predictions mm når vi ikke viser litt omsorg til dataene som faktisk skal prosesseres. Ja, den mørke hemmeligheten til programmering er at til syvende og sist handler det kun om data som skal leses, kalkuleres på og skrives.
Veldig anekdotisk om ytelsespotensiale: I desember deltok jeg (og 431 andre) på knowits kodekalender, og det jeg kanskje fant mest givende med hele den opplevelsen er "sluttspillet" som oppsto da alle de som hadde løst en gitt oppgave kunne diskutere sine løsninger i et eget kommentarfelt. Der så vi løsninger i en mengde språk, i henhold til et knippe paradigmer, ulike algoritmiske tilnærminger og med ulik grad av optimalisering. F.eks. kunne vi for luke 23 observere forskjeller i kjøretid fra 1m52s til <5ms (Takk til terjew for grafen! Denne viser kjøretid, så det er noe usagt her rundt minnebruk naturligvis). Nå er heller ikke problemene vi ble konfrontert med der nødvendigvis direkte 1:1 sammenliknbare for hva folk flest løser til daglig, men det viste fortsatt mye av spennet av hva valg av algoritme, teknologi samt omsorg for maskinvare kan ha å si. Python-løsningen som kjørte på ~30s var en helt kurant løsning i seg selv (ganske pythonistisk for hva jeg er i stand til å bedømme), mens en tilsvarende ganske naiv løsning i C først havnet på ~1s enkelttrådet, og ~0.23s 8-trådet, før det så oppstod en kollaborativ innsats der en mindre gruppe virkelig begynte å se hvor langt man klarte å dra det. Her kan vi selvsagt diskutere avkastningen i forhold til tiden brukt for å ta oss hele veien ned til ~5ms - og dette vil være avhengig av faktisk problemdomene.
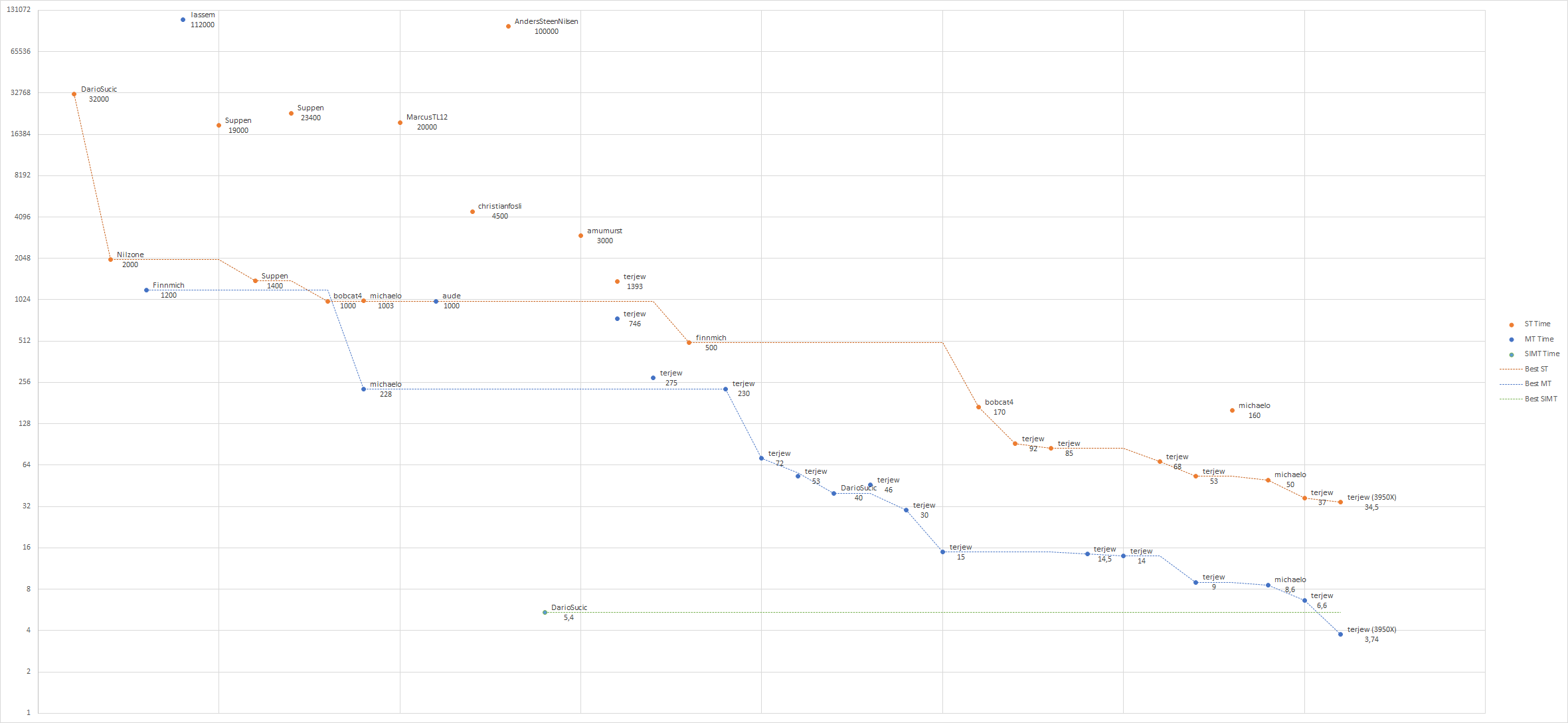{kind=link}
Bare for å ha det sagt: vi så også C++-løsninger opp i 20s-spekteret, dette er ikke kun et poeng om språk og kompilator. Det er i de fleste forslagene der brukt ulike algoritmiske tilnærminger og mange av målingene er gjort på ulik maskinvare - spesielt initielt. De observante vil også se at de (kjøretids-)effektive løsningene gjerne også bestod av mer kode og sånn sett kan øke risikoen for feil samt gjør det vanskeligere å tilpasse over tid. Det er ikke en løsning å hyperoptimalisere alt, men jeg føler det fortsatt sier noe om potensialet ved å legge litt kjærlighet i det man lager.
En annen tanke: Det jeg forøvrig kunne tenke meg er å se noen vurderinger gjort på et makroperspektiv, der man ser på dette sammen med f.eks. størrelsen på serverparkene til Google, Microsoft, Facebook og Amazon. Det er et miljøperspektiv her: Disse skal produseres, forsynes med strøm, og etterhvert deponeres/gjenvinnes. Hva ville det gjort om gjennomsnittsforbruket av RAM for en gjennomsnittlig applikasjon redusertes med 10%? 20%? 50%? Og dette samsvarende med tilsvarende økning i effektiviteten av CPU-bruk? Det finnes riktignok tider hvor man må gjøre et kompromiss av typen: bruke mere RAM for å redusere CPU-belastning, eller omvendt, men jeg vil allikevel påstå at det i mange tilfeller er mulig å forbedre begge to.
Jeg har en frykt - som jeg ønsker å finne kvalitative tall for eller mot på, men har ikke lykkes så langt - om at programvarekompleksitet (herunder systemer) øker raskere enn maskinvareytelsen. I så fall er mye av praten rundt horisontal skalering (dvs som standard go-to-løsning ved ytelsesproblemer) og tilsvarende aspekter av skyløsninger å anse som kortsiktig tenking: vi har kjøpt oss litt tid, det fungerer umiddelbart, men hvor mye løser det egentlig på lang sikt hvis dette fortsetter slik?
Om testkode
Jeg kaster inn en liten parentes som lyder som følger:
[...] (gjerne akkompagnert med 2:1 testkode:kode-ratio) [...]
En ørliten klarifisering: Det er ikke slik at jeg er imot testkode (automatiserte tester realisert som kode) - tvert imot. Det er et fantastisk bra og viktig verktøy. I tillegg var ikke 2:1 det mest illustrative forholdstallet rundt hva som er å anse problematisk mengde. Jeg tenker her også på automatiserte tester generelt, og knytter ikke det direkte for/mot utviklingsmetodologier.
Det jeg ganske enkelt ønsker at utviklere skal være bevisste på er at også dette er med på å øke egenmassen til kodebasen og dermed har en påvirkning på endringsmomentet til en løsning. Velkjente argumenter utover å verifisere at den gitte kodesnutten oppfører som forventet er at de lar deg refaktorere uten frykt samt gir deg en ekstra advarsel ved endring på grensesnittene. Men om man gjør endringer som enten påvirker de eksplisitte avhengighetene (funksjonssignaturer/API-overflate) eller de implisitte avhengighetene (de som - forhåpentligvis utilsiktet og også uønsket - baserer seg på særegenheter i den aktuelle implementasjonen) så må man også oppdatere testkoden tilsvarende. Dette tar tid. Forhåpentligvis er verdien høy nok over tid til å forsvare dette.
Når det kommer til forholdet mellom mengde testkode sett opp mot mengde implementasjonskode, som igjen helst bør ha en viss korrelasjon til faktisk testdekning for å gi mening, så ser jeg det som naturlig at dette samsvarer med kritikaliteten av programvaren som utvikles: Det er forskjell på enkle kommandolinjegrensesnitt, nettsider, små og store nettapplikasjoner, bibliotekskode, rammeverk og safetykritiske systemer. I tillegg bør det være tatt stilling til de potensielt økonomiske implikasjonene feil vil ha. Eller for å snu rundt på det: antall brukere som potensielt vil være påvirket, og i hvilken grad det da vil påvirke de.
Jeg tror ikke noe av det jeg skriver her er sjokkerende, men vet selv hvor lett det er å la seg rive med når endorfinrushet fra dekningsgraden som øker, kombineres med en liten dose tvangstankeliknende stolthet i perfeksjonisme og bransjepåvirkere som trekker relasjoner mellom TDD og hygieniske krav til kirurger.
Opprinnelig kommentar
Det opprinnelige svaret mitt (krever medlemskap i gruppen) var som følger:
En invitasjon til ranting (y) jo =) Jeg tar den jeg.
<rant>
Det er nok dessverre ikke det som vil eksplodere i 2020, men jeg antar at vi kommer til å se fortsettelsen på abstraksjons-og-gjenbruks-toget som har pågått i mange år nå:
Språk, teknologier, rammeverk mm markedsføres (og slukes) på premisset rundt at vi skal i bunn og grunn ikke trenge å forholde oss til det faktum at koden vi skriver faktisk til syvende og sist skal kjøres på hardware, samt en hellig overbevisning at all skriving av egen kode som funksjonelt ligner på noe noen har lagt ut på npm/cargo/maven/nuget/... er unødvendig.
Argumenter som at utviklertid er mer kostbar enn hardware møter seg selv når man
mansnubler over bugs og flaskehalser som kommer fra alt fra underliggende årsaker som man enten ikke forstår til utilstrekkelige og/eller dype abstraksjoner som det vil være fryktelig kostbare å endre da "arkitekturen" f.eks. består av (tilfeldig sammensatt eksempel her altså) en kompilert-til-JS-applikasjon (gjerne akkompagnert med 2:1 testkode:kode-ratio) med 100+ avhengigheter, bundlet med Chromium, pakket inn i en docker-container, kjørende i en eller annen sky/cluster-tjeneste (som gjerne er en abstraksjon over Kubernetes igjen) før det til slutt snakker med et faktisk OS.Og det er ikke akkurat som at OSene vi har i dag er veldig HW-effektive og robuste heller... Dette av historiske grunner, men dog.
Kunne også sagt noe her om bruk av RAM også, der det ikke er uvanlig å høre argumenter som at "ubrukt RAM er sløst RAM" (fritt sitert). Argument som sett i isolasjon kan gi mening (OK nok i et embedded miljø der man har full kontroll på alt som skal kjøre), men som i desktop-miljøer fører til at når man sånn som enkelte av oss ønsker å ha flere applikasjoner kjørende samtidig så trenger man 16GB+ RAM bare for å ha et par utviklingsmiljø-instanser.
(Ja, jeg er klar over at jeg skjærer applikasjon+infrastruktur over samme lest her)
(Og ja, jeg vet at ingen av disse synspunktene har sitt opp
ghav fra meg. Men jeg videreformidler med "glede")(Og alle tall er semi-tilfeldig plukket basert på observasjoner)
</rant>
Obs: Dette var ikke en rant (kun) om web - det har vært symptomatisk innen de områdene jeg har rukket å besøke i mitt yrkesaktive liv.
Ellers ser jeg lyst på tilværelsen jeg altså!